If the routing information is received and forwarded before a calculation is performed, the information must be independent of the calculation. In other words, each router along a route is performing a local calculation independent of any other router's calculation, and the result of each router's calculation is not shared with other routers. If the calculations are local, it is imperative that all routers along a route derive the same conclusions so that packets are forwarded consistently. Therefore, the information must be exactly the same for each router. No router can alter the information in any way as it is passed along.
If no router is sharing the results of its route calculations with any other router, the only thing it can know before any calculation is itself and its directly connected links
It is not enough, however, for some router a number of hops away from the destination to receive an announcement of, "I am router A, and I have a directly connected subnet of X." The receiving router must still know how to reach router A. Therefore, every router in the network must send an announcement identifying itself, its links, and the cost associated with each link.
One final piece of information must be included in the individual announcements for everything to work properly:
Each router must not only identify itself and its directly connected links, but must also identify any directly connected neighboring routers on those links
• Every router in a network sends Hello messages on its local links and listens for Hellos, to discover neighboring routers.
• Every router sends an announcement identifying itself, its directly connected links, and its directly connected neighboring routers.
• Every router receiving an announcement keeps a copy of the announcement in a database, and forwards the announcement to its downstream neighbors.
• When a router has a copy of an announcement from every other router in its database, it can accurately calculate routes to destinations.
Therefore, each link state router has a router ID (RID), which is an address unique to each router within a single routing domain. The router ID can be administratively assigned, or it can be automatically derived by some means such as using an interface address. The only requirement is that it must be different from the ID used by any other router in the domain, and it must be consistent a router cannot identify itself differently to different neighbors.
When 2 routers have verified two-way communication, by seeing each other RID. This method of handshaking is called three-way handshaking. I see you, an you see me.
Every router in the network must receive every announcement and record a copy in its database. The process of getting the announcement to every router is called flooding
To guarantee "sameness," no router can modify another router's announcement. That means that every router is responsible for its own announcements
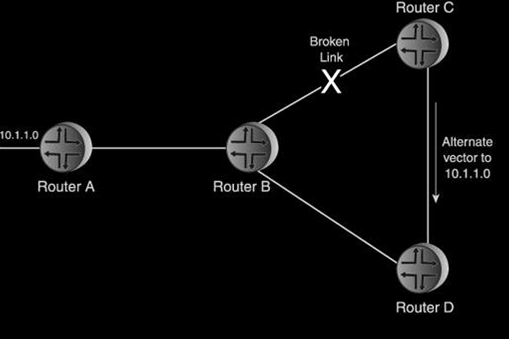
If the failure is a protocol daemon or the router itself, neighbors will detect the failure through the loss of Hello messages. In either case, the effected neighbors send new announcements indicating the change.
But now there can be a dilemma. If router A fails, nonadjacent routers receive announcements from A's adjacent neighbors indicating the loss of A. But these routers also still have A's link announcement in their databases. What should be done with those announcements? Can the other routers safely deduce that A has failed and remove A's announcement? Is this a violation of the rule that no router can modify another router's announcement? And more important, how can each router be confident that all other routers have removed the announcement, to preserve database consistency?
To help resolve this dilemma, link state protocols include an age field in each link announcement. When a router originates an announcement, it sets a value in the age field
This value is changed (either incremented or decremented)[ OSPF increments the age, whereas IS-IS decrements it.] by other routers during flooding, and by every router as the announcement resides in its database. Some absolute value is specified in the protocol at which, if the age reaches this value, the announcement is declared invalid or "aged out," and is deleted from the database. The originating router is responsible for sending a new copy of the announcement at some time prior to this age expiration. The origination of a new announcement is called a refresh. In our example scenario, router A's announcement ages out in all databases because A is no longer refreshing the announcement. Every router in the network then has some assurance that as it deletes A's announcement, all of the other routers are also deleting the announcement
An announcement will be replicated numerous times during flooding, and as a result some routers will receive multiple copies of the same announcement. If all announcements arrive at the same time, any announcement can be chosen. Of course, delays across different network paths back to the originator are going to vary, so in most cases the multiple copies of the same announcement arrive at different times. In this case, the router might simply accept the announcement with the lowest age, on the grounds that the lowest age indicates the newest announcement.
It is entirely possible that delay variations in the network could cause an updated announcement to arrive with a greater age than the first announcement, causing the second announcement to be incorrectly dropped. Therefore, age is not a reliable determinant for choosing the most recent announcement. A
second value, the sequence number, specifies the most recent version of a router's announcement. Given two announcements from the same router, the announcement with the higher sequence number is newer
The simplest sequence numbering scheme is a linear one: A sequence number starts at zero, and increments up to some maximum. For example, a 32-bit sequence number (used by both OSPF and IS-IS) can range from zero to 232, or about 4.3 billion. If a router always starts numbering its announcements at sequence number one, this many available numbers should last far beyond the lifetime of the router. Even if a router produces a new announcement every second a sign of a very unstable link the maximum sequence number would not be reached for more than 130 years
If for some weird reason the router reaches the max counter it has to be reset to 1, If a new announcement is sent with a sequence number of 1, that announcement will be viewed by other routers as an older announcement and will be rejected. To avoid this situation, the router must wait until the existing announcement ages out of all databases
A better approach is for the router cycling its sequence numbers back to the beginning to first cause its previous announcement to be deleted from all databases. The router can do this by issuing another copy of the announcement with the maximum sequence number, but with the age set to a value indicating that the announcement's age has expired. (MaxAge or 0, depending on whether the age counter is up-counting or downcounting).
For example, if there is a 32-bit sequence number space, the number after 4,294,967,295 is 0. However, there is the potential for confusion in this scheme. Suppose two announcements are received from a router, one of which has a sequence number of 1000 and one with a sequence number of 10. The sequence numbers are not contiguous; so is the first announcement newer, or has the sequence number restarted, making the second number higher?
a > b, and (a - b) < n/2
a < b, and (b - a) > n/2
n = 64
and
n/2 = 32.
Given two sequence numbers 48 and 18, 48 is more recent because by the first rule
48 > 18 and (48 18) = 30, and 30 < 32.
Given two sequence numbers 3 and 48, 3 is more recent because by the second rule
3 < 48 and (48 3) = 45, and 45 > 32.
Given two sequence numbers 3 and 18, 18 is more recent because by the first rule
18 > 3 and (18 3) = 15, and 15 < 32.
Although a circular sequence number space seems better than a linear one, an odd series of simultaneous errors in a circular sequence number space can cause a network outage much worse than what sequence number rollover in a linear space causes. This determination is based on a meltdown of the ARPANET on October 27, 1980, when an early link state protocol with a 6-bit circular sequence number space was being used. As a result of that experience, both OSPF and IS-IS use linear sequence numbers.
The last issue with sequence numbers is what happens when a router or protocol restarts and loses all memory of what its last sequence number was. It cannot start again at the beginning, because other routers are likely to have an old announcement from the router in their databases with a higher sequence number, in which case the other routers would reject the new announcement with the lower sequence number. Therefore, another rule is added.
When a link state protocol starts, the router sends its announcement with a sequence number of 1 (or whatever the beginning sequence number is for that protocol). If a neighbor has an announcement from the router in its database with a more recent sequence number, it sends a copy of the announcement to the router. The router can then look at the sequence number and begin numbering its new announcements one higher than that number.
A checksum is performed over the entire contents of a link state announcement with the exception of the age field. Because the age changes as the announcement passes through routers during flooding, including it in the checksum would mean recalculating the checksum every time the age changes.
The age of every announcement is tracked, and if the originating router does not refresh the announcement before the age limit is reached, the announcement is deleted from the database.
An announcement is completely differentiated by its header, only the header needs to be sent during the phases of synchronization in which a neighbor is describing the announcements in its database and when a router is requesting a copy of the announcements it does not have.
The costs assigned to the links do not have to be the same at both ends of the links. The costs are assigned to the router interfaces connecting to the links, and apply to outgoing traffic on those interfaces. This way, traffic flows between two routers across the network can be made asymmetric
All routers in one area must have an identical link state database, rather than all routers in the entire routing domain. The flooding of individual router announcements is limited to the boundaries of an area.
Rule says that all routers within an area must have the same link state database, so area border routers
must maintain separate link state databases for each area to which they are attached. The scope of the trees calculated by the routers internal to an area is the area boundary. Area border routers calculate multiple trees, one for each of its attached areas.




{kind=link}
{kind=link}